" transform="translate(5.642 8.618)" width="9.408882000000037px"/></svg>)
" height="1.3818000000000001px" id="Do7XGZl95" transform="translate(1.177 10.861)" width="2.6402849999999916px"/><path d="M 0 0 L 2.64 0.97 L 2.64 1.381 L 0 0.408 Z" fill="rgb(243, 243, 243)" height="1.3811250000000008px" id="ardUqVSjv" transform="translate(17.019 8.255)" width="2.640225000000015px"/><path d="M 2.54 2.764 L 1.148 1.41 C 1.13 1.393 1.101 1.393 1.084 1.41 L 0.336 2.138 L 0 1.811 L 1.861 0 L 2.197 0.327 L 1.438 1.065 C 1.421 1.082 1.421 1.11 1.438 1.127 L 2.83 2.481 Z" fill="rgb(243, 243, 243)" height="2.7642000000000007px" id="XSm8bSs0k" transform="translate(2.442 13.382)" width="2.8302900000000193px"/><path d="M 0.291 0.001 L 1.682 1.355 C 1.7 1.372 1.728 1.372 1.746 1.355 L 2.505 0.617 L 2.841 0.944 L 0.98 2.755 L 0.644 2.428 L 1.392 1.7 C 1.41 1.682 1.41 1.654 1.392 1.637 L 0 0.283 L 0.291 0 Z" fill="rgb(243, 243, 243)" height="2.7545849999999996px" id="f2ZZLAsi4" transform="translate(15.559 4.358)" width="2.8407749999999794px"/><path d="M 1.103 2.422 L 1.103 0.507 C 1.103 0.482 1.083 0.463 1.058 0.463 L 0 0.463 L 0 0 L 2.632 0 L 2.632 0.463 L 1.559 0.463 C 1.534 0.463 1.515 0.482 1.515 0.506 L 1.515 2.421 L 1.104 2.421 Z" fill="rgb(243, 243, 243)" height="2.421900000000001px" id="tc4qemIbM" transform="translate(1.186 8.257)" width="2.6324024999999835px"/><path d="M 0.297 0 L 2.871 1.128 L 2.572 1.419 L 0 0.289 Z" fill="rgb(243, 243, 243)" height="1.418872499999999px" id="hhCAOkrMa" transform="translate(2.435 5.013)" width="2.871052500000019px"/><path d="M 0.001 1.088 L 1.969 1.088 C 1.994 1.088 2.014 1.068 2.014 1.044 L 2.014 0 L 2.489 0 L 2.489 2.561 L 2.014 2.561 L 2.014 1.532 C 2.014 1.508 1.993 1.488 1.968 1.488 L 0 1.488 L 0 1.088 Z" fill="rgb(243, 243, 243)" height="2.5613850000000005px" id="OMqPlHb47" transform="translate(9.977 1.259)" width="2.4891000000000076px"/><path d="M 0 2.569 L 0.997 0 L 1.419 0 L 0.419 2.569 Z" fill="rgb(243, 243, 243)" height="2.5690575000000004px" id="aEfuntreb" transform="translate(8.37 1.259)" width="1.419374999999988px"/><path d="M 0 1.13 L 2.572 0 L 2.871 0.291 L 0.296 1.419 Z" fill="rgb(243, 243, 243)" height="1.4188725000000009px" id="mFAuf88mE" transform="translate(13.637 3.169)" width="2.8710750000000047px"/><path d="M 0 2.471 L 1.392 1.117 C 1.41 1.1 1.41 1.072 1.392 1.055 L 0.644 0.327 L 0.98 0 L 2.841 1.811 L 2.505 2.138 L 1.746 1.4 C 1.728 1.382 1.7 1.382 1.682 1.4 L 0.291 2.754 Z" fill="rgb(243, 243, 243)" height="2.7539474999999998px" id="AklTveDxG" transform="translate(4.359 2.489)" width="2.840804999999989px"/><path d="M 0 2.504 L 1.159 0 L 1.458 0.291 L 0.297 2.794 Z" fill="rgb(243, 243, 243)" height="2.793599999999998px" id="cxf8oZVTx" transform="translate(5.036 15.224)" width="1.458209999999994px"/><path d="M 2.489 1.488 L 0.521 1.488 C 0.496 1.488 0.475 1.508 0.475 1.532 L 0.475 2.561 L 0 2.561 L 0 0 L 0.475 0 L 0.475 1.044 C 0.475 1.068 0.496 1.087 0.52 1.087 L 2.488 1.087 L 2.488 1.487 Z" fill="rgb(243, 243, 243)" height="2.561399999999999px" id="hHtvwCwnw" transform="translate(8.37 16.672)" width="2.489024999999984px"/><path d="M 1.001 2.568 L 0 0 L 0.423 0 L 1.42 2.568 Z" fill="rgb(243, 243, 243)" height="2.568375000000003px" id="BH16vA6Yx" transform="translate(11.045 16.673)" width="1.4200499999999892px"/><path d="M 2.83 0.283 L 1.439 1.637 C 1.421 1.654 1.421 1.682 1.439 1.699 L 2.197 2.437 L 1.861 2.764 L 0 0.953 L 0.336 0.626 L 1.084 1.354 C 1.102 1.372 1.131 1.372 1.149 1.354 L 2.54 0 L 2.831 0.283 Z" fill="rgb(243, 243, 243)" height="2.7642000000000024px" id="XPK73E3YK" transform="translate(13.643 15.253)" width="2.8309500000000156px"/><path d="M 1.515 0.001 L 1.515 1.916 C 1.515 1.94 1.535 1.959 1.559 1.959 L 2.632 1.959 L 2.632 2.422 L 0 2.422 L 0 1.959 L 1.058 1.959 C 1.083 1.959 1.103 1.94 1.103 1.915 L 1.103 0 L 1.514 0 Z" fill="rgb(243, 243, 243)" height="2.4219749999999998px" id="w7PYPX9i3" transform="translate(17.027 9.82)" width="2.632425000000012px"/><path d="M 0.297 0 L 1.459 2.503 L 1.16 2.794 L 0 0.289 Z" fill="rgb(243, 243, 243)" height="2.7936000000000014px" id="F5j_VjIZW" transform="translate(16.236 13.382)" width="1.4588999999999999px"/></svg>)
" transform="translate(8.844 6.705)" width="3.3157894736842106px"/></svg>)



Human Picks
Staff

A OpenAI apresentou uma nova etapa na geração de imagens do ChatGPT que deixa clara a estratégia por trás do GPT Image 1.5: a proposta vai além da melhoria da qualidade visual e busca transformar o ChatGPT em um hub criativo integrado, no qual gerar, ajustar e refinar imagens acontece dentro da própria conversa, sem a necessidade de alternar entre outras ferramentas.
Esse movimento não é casual e revela uma intenção comercial clara de consolidar o ChatGPT como plataforma central para processos criativos que, até então, permaneciam fragmentados. Ao manter o usuário dentro do próprio ecossistema, a OpenAI reduz a dependência de soluções externas e passa a disputar espaço com outras gigantes, como Google e ByteDance.
Não se trata apenas de estética, já que o GPT Image 1.5 avança tanto em qualidade quanto em fluidez, com um foco evidente na experiência do processo criativo. O objetivo é criar um ambiente no qual seja possível pensar visualmente, testar caminhos e ajustar imagens sem fricção, alcançando resultados mais consistentes ao longo das iterações. No curto prazo, essa aposta já demonstra potencial.
O que realmente muda quando o fluxo do ChatGPT importa mais que resultados isolados
A evolução do GPT Image 1.5 em relação às versões anteriores aparece principalmente em ganhos estruturais que impactam diretamente o fluxo de trabalho. Em comparação com o GPT Image 1.0 e com o DALL·E 3 integrado ao ChatGPT, a compreensão de contexto se tornou mais consistente, reduzindo frustrações ao ajustar detalhes específicos ao longo da conversa. Antes, pequenas mudanças frequentemente “resetavam” a imagem ou geravam alterações não solicitadas. Agora, o modelo demonstra maior memória visual do que já foi estabelecido.
A preservação de identidade visual ao longo de iterações sucessivas também melhorou. Em versões anteriores, manter coerência estética exigia reescrever prompts inteiros ou aceitar variações imprevisíveis. No GPT Image 1.5, essa continuidade acontece com menos esforço, ainda que não seja perfeita em todos os cenários.

A edição localizada avançou de forma perceptível. Remover elementos, trocar fundos ou ajustar composições ficou mais confiável, mesmo que ainda existam limitações claras em projetos que exigem controle extremamente preciso ou proporções rigorosas. O modelo mostra maior clareza sobre o que deve ser alterado e o que precisa ser preservado, reduzindo tentativas frustradas e acelerando a experimentação visual.
Testes práticos mostram que o GPT Image 1.5 consegue realizar edições pontuais, como alterar a cor de uma camiseta ou adicionar e remover objetos mantendo intactos fundo, rosto e outros elementos da composição. Em versões anteriores, ajustes simples frequentemente geravam alterações indesejadas em áreas não solicitadas.
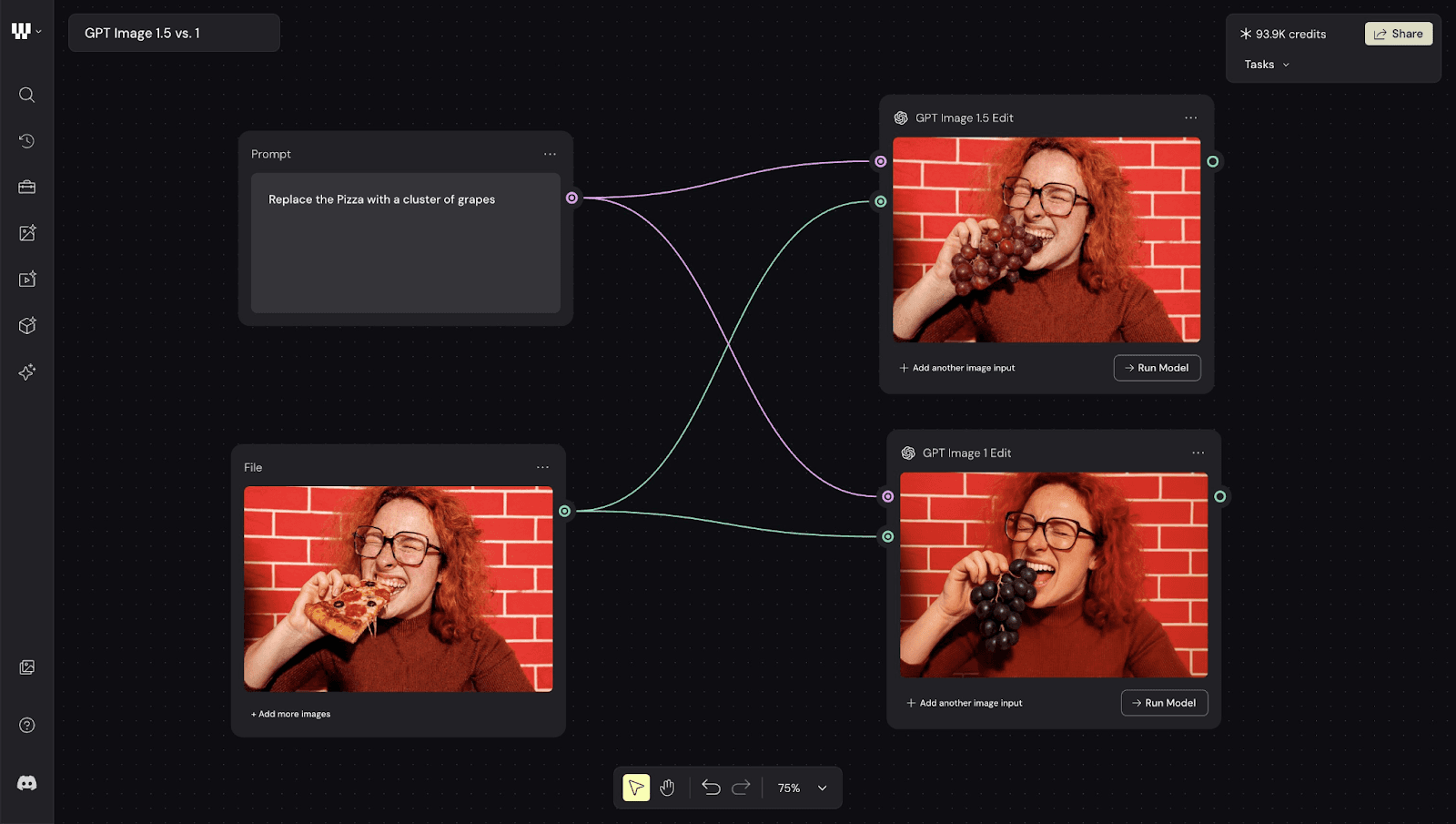
Uma das mudanças mais comentadas entre usuários é a redução do tom amarelado (yellow tint) característico que marcava as gerações anteriores do GPT. Embora ainda apareça em alguns casos, sua frequência diminuiu, tornando os resultados mais neutros e menos imediatamente identificáveis como imagens geradas por IA.

O modelo também passou a lidar melhor com cenas complexas, com múltiplos elementos interagindo sem comprometer a coerência visual. Transformações criativas ficaram mais estáveis, permitindo explorar direções visuais mais ousadas sem perder a estrutura geral da composição.

Ainda assim, a experiência não é totalmente uniforme. Em trabalhos que exigem múltiplas imagens de um mesmo personagem ou cena, a consistência pode variar entre gerações, com diferenças sutis de estilo ou interpretação visual.
Esses pontos são especialmente relevantes em fases iniciais de projetos, quando o objetivo é explorar ideias, testar caminhos e refinar conceitos. O GPT Image 1.5 torna esse processo mais contínuo e menos travado, o que já representa um ganho significativo para quem utiliza a ferramenta com frequência.
O raciocínio visual do GPT Image 1.5 e a continuidade do pensamento criativo
O GPT Image 1.5 atua como uma extensão do raciocínio visual dentro do ChatGPT, entendendo a intenção, contexto e limites criativos de forma integrada. A geração acontece dentro de uma conversa contínua, alterando a dinâmica do processo: a ideia evolui ao longo do diálogo, em vez de cada imagem ser tratada como um pedido isolado.
Essa abordagem reduz o atrito entre concepção e execução visual. Em vez de alternar entre plataformas, exportar arquivos ou reconstruir prompts do zero, o usuário mantém o foco no desenvolvimento da ideia. O histórico da conversa permanece acessível, facilitando ajustes sucessivos e decisões estratégicas ao longo do processo.
A geração em múltiplas etapas dentro de um único chat permite construir narrativas visuais de forma progressiva. Elementos são refinados ao longo da conversa sem a necessidade de reconstruir todo o contexto a cada nova interação, algo valioso em processos de concept art, por exemplo.
O uso do GPT Image 1.5 revela tanto potencial quanto limites
Em um teste prático, o designer Daniel Rodrigues, da Every, utilizou o GPT Image 1.5 como ponto de partida para explorar uma cena complexa, com múltiplos elementos, contexto narrativo e especificações visuais detalhadas. O objetivo não era chegar a um resultado final, mas avaliar até que ponto a ferramenta sustentava ajustes sucessivos dentro da mesma conversa.
O prompt inicial era: "A man eating in a Spanish bar. He has medium-brown skin, a mustache, and is wearing a blue button-up shirt. He is eating Spanish potato omelette, with several plates of food on the table. The bar looks real and busy, with bottles and objects in the background. On the wall in the background, there is a calendar for December. The number 16 is circled with a marker. Realistic photo style."

A primeira geração apresentou atmosfera e composição consistentes. O ambiente tinha traços reconhecíveis de um bar espanhol, o personagem parecia adequado ao contexto e a tortilla (omelete de batata típica da Espanha) estava visualmente coerente.
No entanto, ao tentar fazer ajustes sucessivos dentro da mesma conversa, os problemas começaram a aparecer. Daniel pediu para adicionar uma mulher asiática à cena, depois um namorado, um chihuahua, trocar a comida na mesa por um carbonara e a data no calendário de 2021 para 2025.

A cada nova instrução, o modelo começou a perder consistência. Os braços da mulher adicionada ficaram anatomicamente incorretos, com proporções estranhas e articulações impossíveis. O namorado simplesmente não apareceu na imagem, apesar de ter sido explicitamente solicitado. A comida foi se transformando em um híbrido visual confuso, que não se parecia nem com a tortilla original nem com o novo prato pedido. O cachorro, quando apareceu, estava em uma escala incompatível com o resto da cena.
O modelo estava tentando incorporar novos elementos mantendo a estrutura da imagem anterior, mas sem conseguir reorganizar a composição de forma coerente. Era como se cada pedido fosse sendo empilhado sobre o anterior sem repensar a cena como um todo.
Ao iniciar uma nova conversa com o prompt completo e ajustado, incluindo todos os elementos desejados desde o início, os resultados melhoraram de forma significativa. A cena pareceu natural, os personagens tinham proporções corretas, a comida era reconhecível e a composição geral fazia mais sentido.

Isso revela um limite importante do modelo: o GPT Image 1.5 lida bem com ajustes sucessivos simples, como mudar cores ou remover elementos. Mas edições muito complexas, que envolvem adicionar múltiplos personagens ou reorganizar completamente a cena, tendem a se beneficiar de um "reset" de contexto. Reconstruir o prompt do zero produz resultados melhores do que tentar empilhar muitas mudanças estruturais na mesma thread.
Para equipes de marketing, o impacto aparece de outra forma. Profissionais relatam que o GPT Image 1.5 está levando times a repensar o fluxo de criação visual. A integração dentro do ChatGPT permite conceituar campanhas, gerar imagens principais, criar mockups e adaptar visuais para diferentes plataformas em uma única sessão criativa.
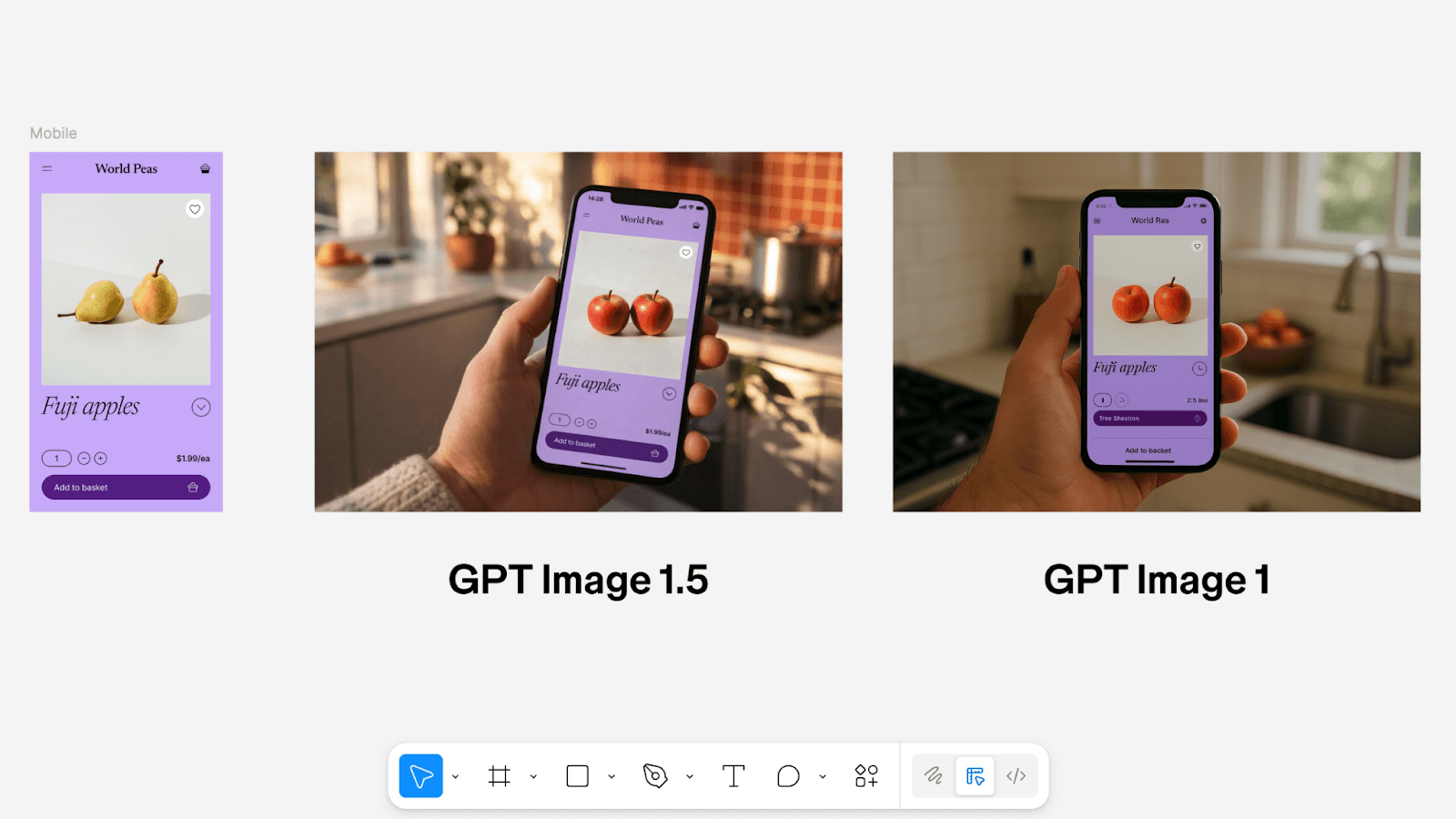
O modelo também demonstra boa compreensão de marca, espaço para tipografia e aplicações comerciais, processando direção criativa e transformação de ativos no mesmo ambiente. Isso reduz a necessidade de alternar entre ferramentas apenas para testar variações visuais.

Ainda assim, há limites claros. O GPT Image 1.5 funciona bem para certos tipos de imagem, como cartões, fotos editoriais, brinquedos ou ilustrações conceituais, mas também apresenta falhas em tarefas que exigem precisão técnica, como diagramas ou conteúdos educacionais estruturados.
GPT Image 1.5 na prática: o que funciona e o que ainda precisa evoluir
Após semanas de uso, começa a se formar um consenso entre criadores e profissionais sobre os pontos fortes e as limitações do GPT Image 1.5.
O que funciona bem
A redução de bloqueios indevidos por regras de segurança tornou o fluxo mais previsível. Prompts legítimos passaram a ser menos interrompidos, permitindo um trabalho mais contínuo.
A qualidade visual se mantém melhor ao longo das edições. Ajustes pontuais preservam elementos que já funcionam, modificando apenas o que foi solicitado, comportamento que antes era mais instável.

A renderização de texto em infográficos e materiais educacionais evoluiu de forma perceptível, com maior legibilidade e menos necessidade de correções manuais posteriores.

Os resultados realistas também ganharam naturalidade. As imagens se afastam da aparência artificial comum em gerações anteriores, apresentando variações sutis e maior sensação de contexto real.

A consistência visual de personagens melhorou, permitindo gerar múltiplas cenas reconhecíveis, ainda que não seja perfeita em todos os casos.

Além disso, o modelo apresenta maior estabilidade operacional, com menos falhas inesperadas durante o uso contínuo.

Limitações que continuam importando (e não devem ser ignoradas)
Apesar dos avanços evidentes, o GPT Image 1.5 ainda apresenta limitações que permanecem relevantes no uso profissional. A principal delas continua sendo a consistência de personagens em situações menos previsíveis.
Mesmo tendo evoluído nesse sentido, em cenas com ângulos mais variados, poses complexas ou condições de iluminação mais elaboradas, a identidade visual do GPT tende a variar mais do que o desejável. Em projetos pontuais isso pode passar despercebido, mas em fluxos que exigem continuidade rigorosa, essas variações acumuladas se tornam um problema real.

O realismo absoluto segue como um ponto sensível. Em comparações diretas, especialmente em cenas que simulam fotografia cotidiana, o GPT Image 1.5 ainda fica atrás do Nano Banana Pro. As imagens são boas, muitas vezes excelentes, mas pequenos detalhes como textura de pele, objetos secundários e relações espaciais sutis ainda denunciam a origem artificial com mais frequência do que no modelo do Google.


As anomalias anatômicas, embora menos comuns do que em gerações anteriores, não desapareceram. Mãos, dedos e interações físicas mais complexas continuam sendo um teste de estresse para o modelo, principalmente em cenas com múltiplas pessoas ou perspectivas extremas. Esses erros surgem o suficiente para exigir revisão humana em entregas mais críticas.

Outro ponto recorrente aparece em ambientes internos com múltiplas fontes de luz. Nesses cenários, proporções de fundo, mobiliário ou relações de escala podem ficar estranhas, chamando a atenção para a imagem como algo “construído”. A frequência desse problema diminuiu, mas ele ainda aparece em tipos específicos de geração.

GPT Image 1.5 vs Nano Banana Pro vs Seedream 4.5: onde cada modelo se destaca
O cenário competitivo da geração de imagens em 2026 é ocupado por três modelos que já operam em nível profissional: o GPT Image 1.5 da OpenAI, o Nano Banana Pro do Google e o Seedream 4.5 da ByteDance. Apesar de disputarem espaço, eles se comportam de maneiras bem diferentes quando passam pelos mesmos desafios práticos.
Nos comparativos, o Nano Banana Pro ainda se destaca quando o objetivo é alcançar realismo. Em cenas do dia a dia, com pessoas, ambientes reconhecíveis e poucos elementos estilizados, o modelo demonstra maior controle de textura, iluminação e proporções. As imagens se aproximam mais de fotografias reais, com menos sinais visíveis de falhas.
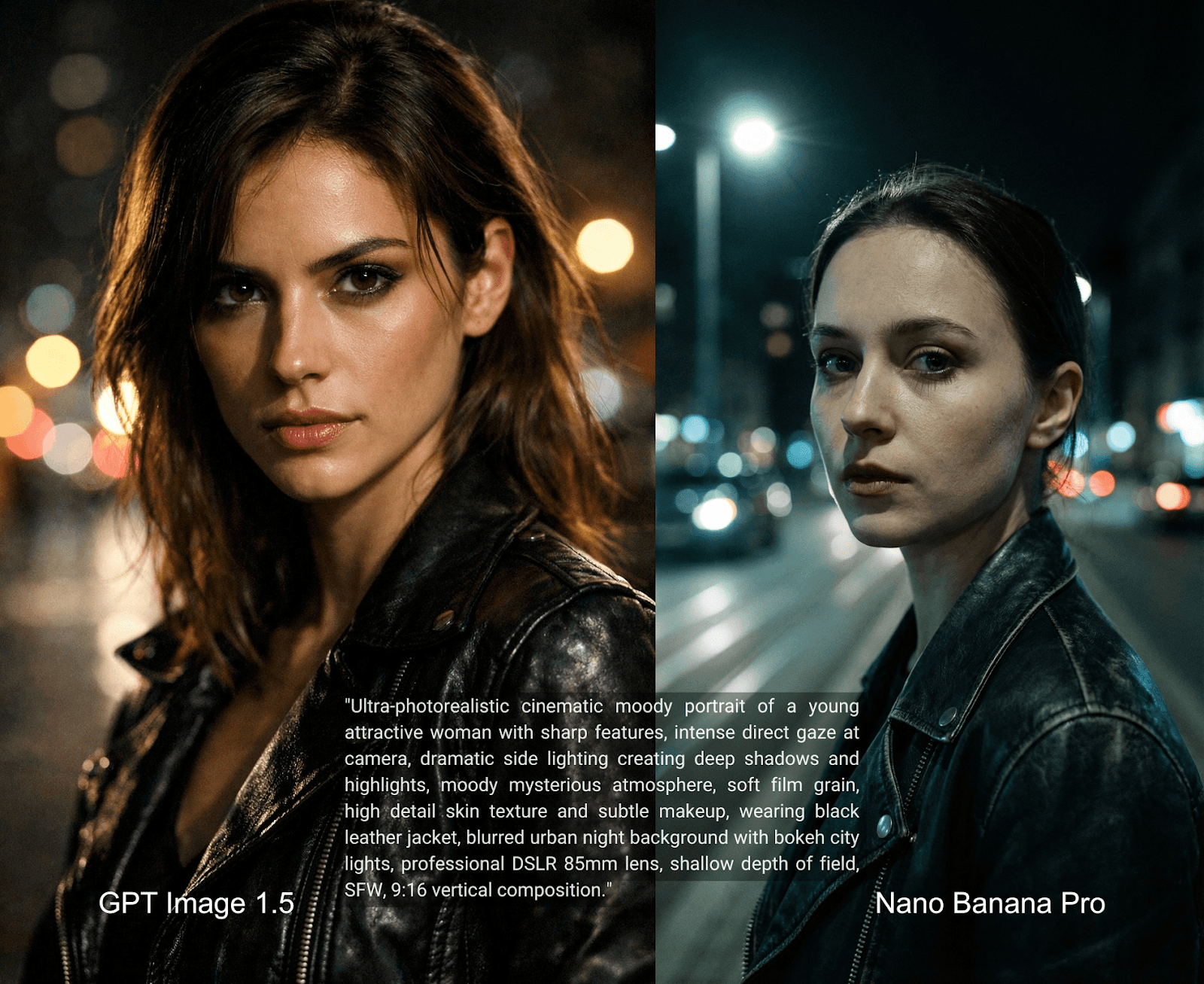
Essa diferença fica clara em comparações diretas usando o mesmo prompt. No teste do bar espanhol que citamos, por exemplo, o Nano Banana Pro apresentou uma leitura mais precisa de contexto cultural, materiais e detalhes secundários da cena. Elementos como comida, expressões faciais e objetos de fundo pareceram mais naturais e coerentes, criando a sensação de uma imagem capturada, não construída.

Essa percepção se repete entre usuários. Mesmo reconhecendo os avanços do GPT Image 1.5, muitos ainda identificam uma “assinatura de GPT” mais perceptível em suas imagens. O Nano Banana Pro, de modo geral, consegue esconder melhor esse traço, especialmente quando o foco é o realismo.
A diferença também aparece na velocidade. Em testes com prompts idênticos, o Nano Banana Pro costuma gerar imagens mais rapidamente, o que influencia sessões de trabalho longas e o ritmo criativo.
O Seedream 4.5 se destaca em outro eixo. Seu principal diferencial está na consistência de identidade ao longo de múltiplas gerações. Em retratos humanos, personagens recorrentes ou séries narrativas, o modelo apresenta um bom nível de estabilidade.

Em testes práticos, o Seedream 4.5 manteve estrutura facial, proporções e textura de pele de forma consistente mesmo após várias iterações. O personagem continua reconhecível, com variações controladas, algo essencial para projetos que exigem continuidade visual.

Essa capacidade se amplia ao trabalhar com múltiplas imagens de referência. O Seedream preserva estilo, iluminação e identidade de forma mais confiável, permitindo edições localizadas sem comprometer o conjunto.

O GPT Image 1.5 ocupa um espaço diferente nesse cenário. Em vez de priorizar realismo absoluto ou consistência extrema, ele demonstra força em composições mais projetadas e no fluxo integrado entre texto e imagem. As imagens apresentam direção de arte clara, com enquadramentos pensados e maior coerência estética ao longo da conversa.

Em cenas mais complexas, como quadrinhos, infográficos, ambientes internos ricos em informação ou layouts com texto, o GPT Image 1.5 mostrou ganhos em storytelling e organização visual. Embora ainda enfrente dificuldades com precisão técnica fina, responde melhor quando a imagem faz parte de um raciocínio maior, não de uma solicitação isolada.

O GPT Image 1.5 veio para substituir outros modelos?
Muitos usuários testam se o GPT Image 1.5 poderia substituir o Nano Banana Pro em seus fluxos de trabalho. Na maioria dos casos, a resposta ainda é negativa. O modelo da OpenAI não se tornou a escolha automática para quem prioriza o ajuste fino ou precisão técnica rigorosa.
O Seedream 4.5, por sua vez, redefine o padrão de consistência de personagem em IA generativa. Para trabalhos que envolvem retratos profissionais, sequências narrativas ou qualquer projeto em que identidade visual precisa ser mantida ao longo de dezenas de imagens, ele se tornou a opção mais confiável.
Não, o GPT Image 1.5 não substitui modelos especializados quando o critério é realismo ou consistência, mas se torna muito útil em fases de exploração, conceituação e produção recorrente de ativos, onde fluidez e integração pesam mais do que perfeição técnica.
No fim, a coexistência desses modelos amplia possibilidades e reduz dependência de uma única ferramenta, deslocando o foco da substituição para a especialização.
Interface vs geração: como a experiência de uso define o resultado
O GPT Image 1.5 oferece uma experiência integrada, voltada à exploração e a ajustes sucessivos dentro do próprio ChatGPT. A interface favorece a experimentação contínua, permitindo que texto e imagem evoluam juntos ao longo da conversa.
O Nano Banana Pro prioriza fidelidade visual e precisão no resultado final. Sua interface é menos orientada à exploração aberta e mais focada em controle do output. O fluxo tende a ser direto: descrever, gerar, avaliar e ajustar.
O Seedream 4.5 ocupa um terceiro território. Sua interface é mais funcional e orientada à consistência do que à experimentação. O foco está no gerenciamento de referências visuais, na manutenção de identidade e no controle fino sobre variações. Não é uma experiência pensada para exploração livre, mas para execução disciplinada.
Trabalhar no Seedream exige mais intenção desde o início. Em contrapartida, a interface recompensa esse rigor com estabilidade ao longo das gerações. Para projetos que envolvem personagens recorrentes, retratos profissionais ou séries visuais extensas, essa abordagem se mostra mais eficiente do que fluxos conversacionais.
Na prática, a escolha da interface influencia diretamente o tipo de processo criativo possível. Para iniciar ideias, testar caminhos e iterar com rapidez, o GPT Image 1.5 funciona melhor. Para demandas que exigem alto grau de realismo e controle técnico, o Nano Banana Pro se destaca. Já o Seedream 4.5 se impõe quando consistência e identidade visual contínua deixam de ser desejáveis e passam a ser obrigatórias.
Aplicações profissionais do GPT Image 1.5: onde o ChatGPT entrega valor real
O GPT Image 1.5 se firma como uma ferramenta relevante para quem pensa visualmente ao longo de todo o processo criativo, e não apenas no resultado final. Seu diferencial aparece quando a imagem acompanha o raciocínio, evolui com a ideia e funciona como instrumento ativo de exploração e refinamento.
Mais do que gerar imagens isoladas, o modelo se integra a fluxos contínuos, nos quais ajustes sucessivos fazem parte da construção visual. É nesse ponto que ele passa de curiosidade tecnológica a ferramenta de trabalho.
E-commerce e varejo digital
Equipes de e-commerce utilizam o GPT Image 1.5 para criar variações de produtos sem novas sessões fotográficas. A partir de um único produto, é possível gerar diferentes contextos, ângulos e ambientes, mantendo fidelidade visual. Isso viabiliza cenas de estilo de vida, adaptações culturais e testes rápidos de catálogo, reduzindo tempo e custo.

Marketing e criação de campanhas
Times de marketing usam a ferramenta para explorar conceitos visuais ainda no brainstorming, criando mockups, testando direções criativas e produzindo variações iniciais sem depender de designers em todas as etapas. A consistência de marca ao longo das gerações facilita campanhas coesas e acelera decisões criativas.
Produção de conteúdo editorial
Criadores e redatores recorrem ao GPT Image 1.5 para gerar capas, ilustrações editoriais e elementos visuais alinhados ao texto, evitando bancos de imagem genéricos. A possibilidade de ajustar atmosfera, tonalidade e composição ao longo da conversa permite um encaixe mais preciso com o tom editorial.

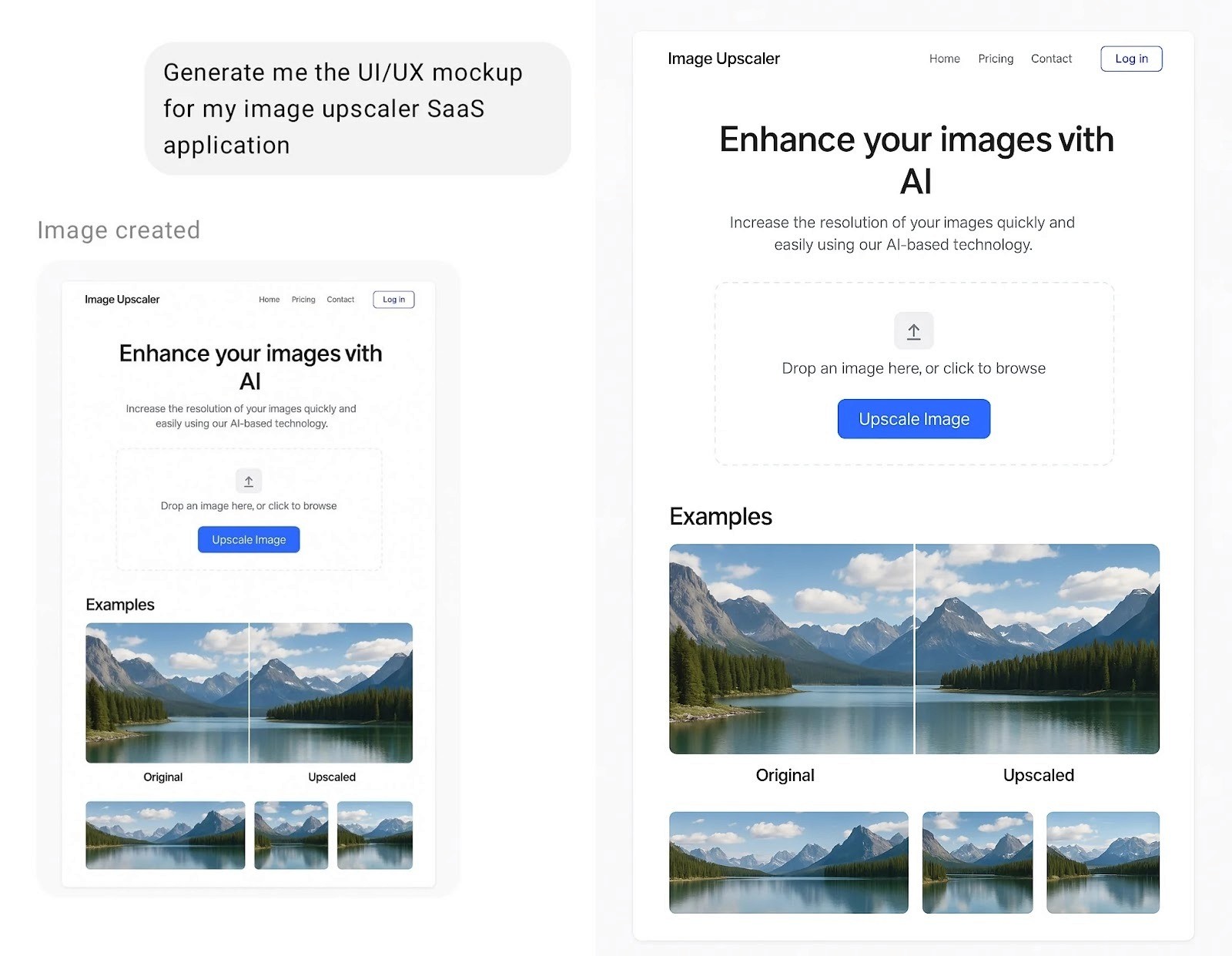
Design de interface e prototipagem
Designers de UX e UI utilizam o modelo para criar mockups rápidos, testar abordagens estéticas e gerar placeholders realistas para apresentações internas. A velocidade de iteração amplia a experimentação e melhora a comunicação com stakeholders antes da produção final.
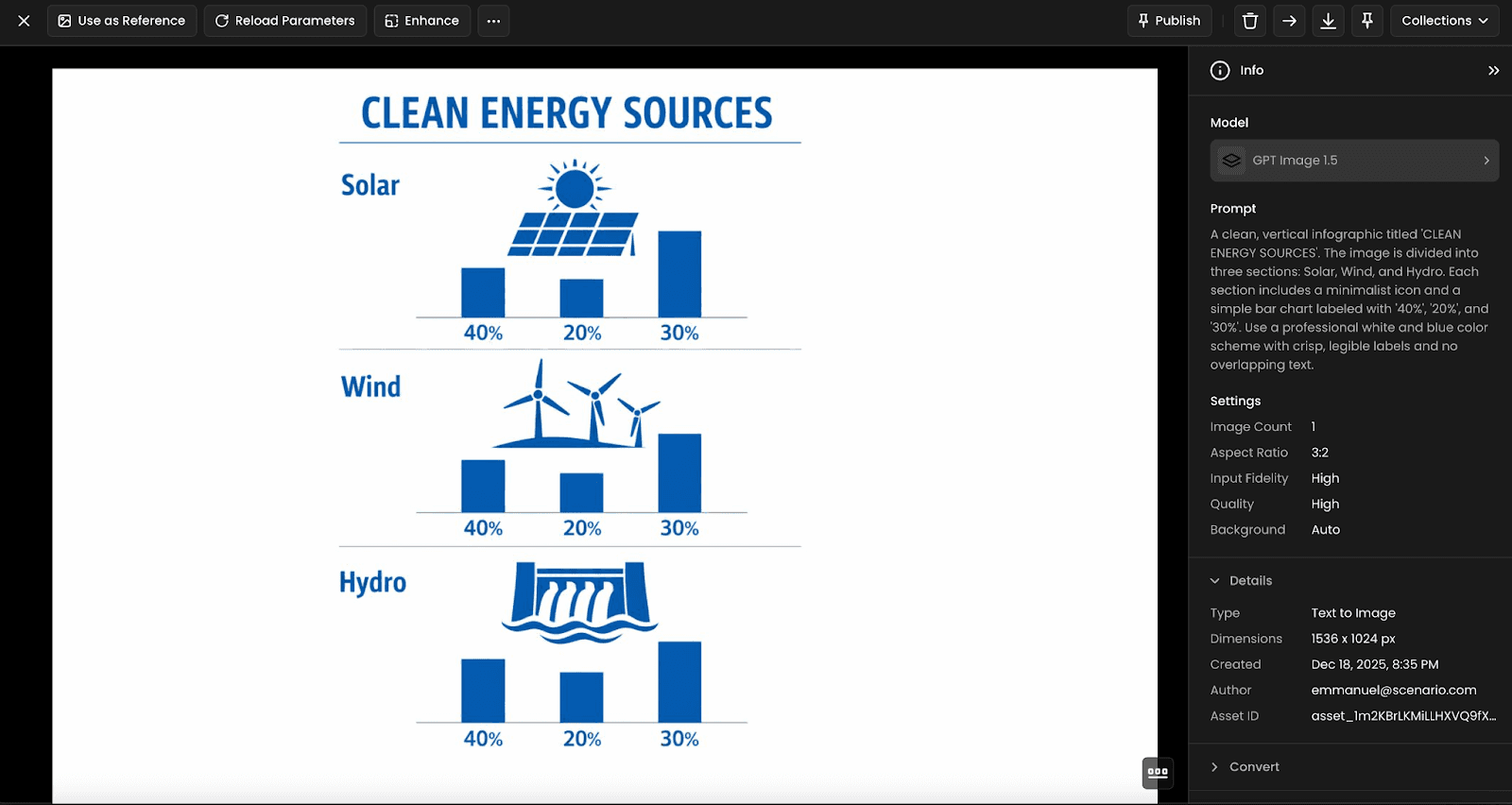
Educação e material didático
Educadores usam o GPT Image 1.5 para criar ilustrações, diagramas e materiais visuais adaptados a contextos específicos. A geração de cenários diversos e representações de conceitos abstratos amplia possibilidades pedagógicas sem depender de produção visual especializada.
Apresentações corporativas e comunicação interna
Equipes corporativas aplicam a ferramenta em apresentações, relatórios e materiais internos, reduzindo o uso de templates genéricos e criando visuais alinhados à identidade da empresa com mais agilidade.
Projetos que exigem controle técnico extremo ou realismo absoluto ainda pedem ferramentas especializadas. Para entregas recorrentes, porém, o GPT Image 1.5 reduz atrito e acelera decisões criativas.
A questão central não é se ele gera a melhor imagem possível, mas se melhora o processo criativo como um todo. Em muitos cenários práticos, a resposta é sim.
Dados iniciais indicam redução de custos e ganho de produtividade em empresas que adotaram o GPT Image 1.5. A capacidade de gerar variações, adaptar visuais para diferentes mercados e manter consistência de marca acelera o ritmo de produção sem comprometer qualidade, especialmente em e-commerce.
Leia também: Como a ia aumentou em até 56% o valor de profissionais criativos em 2025 e por que isso é só o começo
Competição como catalisador: por que criativos são os verdadeiros vencedores da disputa
O GPT Image 1.5 não representa um ponto final na evolução da geração de imagens por IA, mas deixa evidente uma mudança importante na forma como o processo criativo se organiza. O avanço não está apenas na qualidade visual, e sim na integração entre pensar, gerar e refinar imagens dentro de um fluxo contínuo e mais intuitivo.
Em relação ao Image 1.0, a evolução é clara. Há menos erros aleatórios, maior consistência entre versões e uma compreensão mais sólida de cenas complexas. Ainda existem limitações, especialmente quando o objetivo é alcançar realismo extremo ou controle técnico muito preciso, mas o conjunto já reposiciona o ChatGPT como um ambiente criativo viável e funcional.
Dentro de um cenário mais amplo, a disputa entre GPT Image 1.5, Nano Banana Pro e Seedream 4.5 beneficia diretamente quem cria. O mercado se torna mais competitivo e diverso, deslocando o foco do resultado isolado para o processo, a continuidade e a intenção criativa por trás das imagens.
Cada novo lançamento eleva o padrão. Os modelos ficam mais robustos, os resultados mais previsíveis e as possibilidades mais amplas. A competição entre OpenAI, Google e ByteDance reduz barreiras e favorece designers, educadores, pequenos empreendedores e qualquer pessoa com uma ideia visual que antes exigiria mais tempo, equipe e orçamento.
Nesse contexto, o criador segue no centro das decisões. É ele quem define o que comunicar, qual emoção provocar e que história contar. A IA acelera o caminho entre ideia e imagem, permitindo testar, ajustar e compartilhar com mais rapidez, mas não substitui a intenção criativa.
Ter plataformas fortes competindo lado a lado significa poder escolher a ferramenta mais adequada para cada projeto, contar com alternativas e atuar em um ecossistema mais acessível e dinâmico. No fim, a tecnologia amplia possibilidades, mas o diferencial continua sendo inteiramente humano. Repertório, direção criativa, clareza de intenção e boas perguntas seguem decisivos.

